【基本・応用情報技術者】SQL ~SELECT文①~
こんにちは。たろすです。
今回はSQLのSELECT文について説明します。
基本的な使い方
SELECT文はデータベースから特定のデータを取り出すときに使用します。
最も基本的な使い方は以下になります。
SELECT カラム名1, カラム名2,... FROM テーブル名;
これはテーブルから特定のカラム(列)のデータを取ってくる処理を行います。
例えば以下のようなテーブルがあるとします。

これに対し次のようなSQLを投げると、
SELECT 社員番号 FROM 社員;
以下のデータが取れます。

すべてのカラムを取りたい場合は*で取ることができます。
SELECT * FROM 社員;

WHERE句
先程のSQLは条件を絞っていないため、全件が出力されます。
条件で絞る場合はWHERE句を使います。
SELECT カラム名1, カラム名2,... FROM テーブル名 WHERE 条件1 [AND/OR 条件2...];
例えば先程の社員テーブルで役職が部長のレコードを取得したい場合、以下のようなSQLを使用します。
SELECT * FROM 社員 WHERE 役職 = '部長';

このように比較演算子を使えます。
比較演算子には以下があります。
| = | 等しい |
|---|---|
| <> | 等しくない |
| < | 左項より右項が大きい |
| <= | 右項が左項以上 |
| > | 左項より右項が小さい |
| >= | 右項が左項以下 |
複数の条件を使用したい場合はAND(かつ)やOR(または)を使用します。
SELECT * FROM 社員 WHERE 社員番号 = 1000 AND 役職 = '部長';

文字列の場合は' 'で囲みます。
さらに柔軟に条件を指定することもできます。
IN句
IN句では複数の値を指定することができます。
SELECT カラム名1, カラム名2,... FROM テーブル名 WHERE カラム名 [NOT] IN (値1, 値2,...);
社員テーブルから社員番号1000と1001のレコードを取得したい場合は以下のようになります。
SELECT * FROM 社員 WHERE 社員番号 IN (1000, 1001);
逆に社員番号1000と1001以外を取得したい場合はNOTを入れます。
SELECT * FROM 社員 WHERE 社員番号 NOT IN (1000, 1001);

LIKE句
部分一致で取得したい場合はLIKE句を使用します。
SELECT カラム名1, カラム名2,... FROM テーブル名 WHERE カラム名 [NOT] LIKE パターン;
例えば苗字が「山田」の人を全員取得したい場合は次のようなSQLになります。
SELECT * FROM 社員 WHERE 社員名 LIKE '山田%';
名前の最後が「郎」の人を全員取得したい場合は、
SELECT * FROM 社員 WHERE 社員名 LIKE '%郎';

名前の中に「藤」が入る人を取得したい場合は、
SELECT * FROM 社員 WHERE 社員名 LIKE '%藤%';

となります。
一文字だけを任意の文字で取得したい場合は_を使います。
SELECT * FROM 社員 WHERE 役職 LIKE '_長';

BETWEEN句
範囲を指定したいときはBETWEEN句を用います。
SELECT カラム名1, カラム名2,... FROM テーブル名 WHERE カラム名 [NOT] BETWEEN 最小値 AND 最高値;
例えば社員番号が1001から1003のレコードを取得したい場合は以下のようなSQLになります。
SELECT * FROM 社員 WHERE 社員番号 BETWEEN 1001 AND 1003;



【基本・応用情報技術者】データベースの正規化
こんにちは。たろすです。
今回はデータベースの正規化について説明します。
正規化とは
正規化とはデータの重複を排除し、関連性によってテーブルを分けることです。
正規化をすることにより、データを更新した際の不具合を防ぐことができます。
正規形には第1正規形、第2正規形、第3正規形、ボイス・コッド正規形、第4正規形、第5正規形がありますが、第3正規形までで充分なことがほとんどであり、試験でもほぼ出てこないので第3正規形までを説明します。
非正規形
下のテーブルでは1件の受注情報に対して複数の明細情報が含まれています。

このような繰り返し属性があると実装が難しいため、第1正規形に正規化します。
第1正規形
繰返し属性を持たない下のようなテーブルを第1正規形と呼びます。

第2正規形
第1正規形では以下のようなことが起こります。
・受注実績のない商品を登録できない
・山田花子の受注情報を削除すると、ボールペンの情報がなくなってしまう
そのため、先程のテーブルを下のような第2正規形に正規化します。

これにより上記二つの不具合はなくなったことがわかります。
第2正規形へ正規化されたテーブルでは、すべての非キー属性が主キーに完全関数従属します。
完全関数従属とは非キー属性が主キーの一部によって決まらないということです。
第1正規形のテーブルでいうと、受注日、顧客番号、顧客名、金額は主キーの一部である受注番号のみで決まっています。
また商品名と単価は商品コードのみで決まります。
受注番号と商品コードの両方で特定されるのは数量のみです。
したがって、テーブルを上のように三つに分けることで第2正規形になります。
第3正規形
実は第2正規形にも以下のような不具合があります。
・受注実績のない顧客を登録できない
・受注テーブルの1行目の顧客名を変えると、顧客番号が同じで顧客名が異なる行が生まれる
そこで第3正規形に正規化します。

このように顧客情報を受注テーブルから切り離すことで、上記二つの不具合がなくなったことがわかります。
第3正規形はすべての非キー属性が主キーに対して推移的関数従属しません。
推移的関数従属とは主キー以外の属性に関数従属することです。
第2正規化では顧客名が非キー属性の顧客番号によって決まってしまっていました。
そこで顧客番号と顧客名を顧客番号を主キーとするテーブルに切り離すことによって推移的関数従属がなくなりました。
おわりに
今回はデータベースの正規化について説明しました。
直接問われることは少ないですが、データベースの問題を解くときには基礎となる知識なので覚えておきましょう。
【基本・応用情報技術者】データベースの候補キー、主キー、複合キー、外部キー
こんにちは。たろすです。
今回は候補キー、主キー、複合キー、外部キーについて説明します。
候補キー
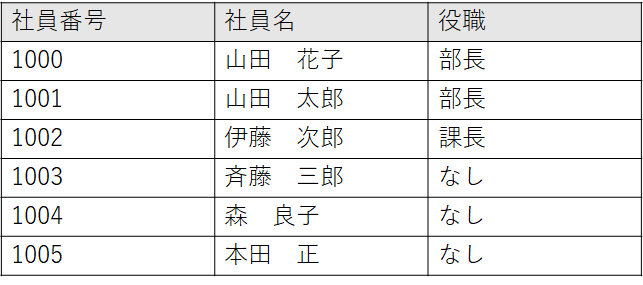
タプル(行)を一意に識別できる属性(列)の集合のうち極小のものを候補キーといいます。
下のテーブルでは{社員番号}、{社員名}、{社員番号,社員名}でタプルを特定できますが、社員番号か社員名のどちらかのみで特定できるため候補キーは{社員番号}と{社員名}になります。
主キー
候補キーのうちの一つが主キーとなります。
主キーには以下の条件があります。
一意性制約(ユニーク制約):その列の中に重複するデータがあってはならない
非ナル制約:その列の中にNULLがあってはならない
先程のテーブルでは候補キーが二つあってどっちを主キーにすればいいの?となると思いますが、一般的には社員番号を主キーにします。
なぜなら社員名は今後社員が増えたときに絶対に重複しないとは言えないからです。
主キーの属性名には下線を引くことで主キーであることを示します。
複合キー
主キーは一つの属性であるとは限りません。
属性の組み合わせを主キーとする場合もあります。
そのときの主キーを複合キーと呼びます。
例えば下のテーブルでは商品番号だけではタプルを一意に識別できません。
なので商品番号と連番の複合キーとなります。

外部キー
他のテーブルの主キーを参照する属性を外部キーといいます。
外部キーとなる属性のデータは必ず参照先の列に存在しなくてはなりません。

なお外部キーの属性名には点線を引きます。
【基本・応用情報技術者】論理回路
こんにちは。たろすです。
今回は論理回路について説明します。
論理式の知識が前提になるので、論理式がわかっていない方はこちらから押さえておきましょう。
論理ゲートの種類
論理ゲートは6種類あります。
基本情報技術者試験や応用情報技術者試験ではMIL記号と呼ばれる表記で論理回路が書かれているのですが、それぞれの記号がなにを表しているのかは提示されるため必ずしも覚える必要はありません。
ただ時間をかけないためにも覚えることを推奨します。
AND

を表しています。
OR

を表しています。
NOT

を表しています。
NAND

を表しています。
NOR

を表しています。
XOR

を表しています。
例題
論理回路図を使った問題を解いてみましょう。
問題
図に示すディジタル回路と等価な論理式はどれか。ここで,論理式中の"・"は論理積,"+"は論理和,XはXの否定を表す。

ア.
イ.
ウ.
エ.
(出典:平成29年度 秋期 基本情報技術者試験 午前 問23)
解説
各ゲートの入力と出力を見ていきましょう。
二つのNOTゲートにはそれぞれと
が入力され、
と
が出力されます。

一つ目のORゲートにはと
が入力され、
が出力されます。

上側のANDゲートにはと
が入力され、
が出力されます。
下側のANDゲートにはと
が入力され、
が出力されます。

最後のORゲートにはと
が入力され、
が出力されます。

もちろん選択肢にこの回答はないため、変形する必要があります。
したがって答えはウになります。
【基本・応用情報技術者】ラウンドロビン方式
こんにちは。たろすです。
今回はスケジューリングの方式のひとつ、ラウンドロビン方式について説明をします。
スケジューリングの説明は以下の記事でしています。
https://talosta.hatenablog.com/entry/schedulingtalosta.hatenablog.com
ラウンドロビン方式
プロセスにCPUを割り当てられる時間(=タイムクォンタム)が決められており、タイムクォンタム分実行したら待ち行列の最後尾に並べる方式です。
ラウンドロビン方式は基本情報技術者試験や応用情報技術者試験でよく問われます。
なぜかというと、他の方式と比べると複雑だからです。
なので例題を解きながら詳しく見ていきましょう。
例題
問題
タイムクウォンタムが2秒のラウンドロビン方式で処理されるタイムシェアリングシステムにおいて,プロセス1~3が逐次生成されるとき,プロセス2が終了するのはプロセス2の生成時刻から何秒後か。ここで,各プロセスはCPU処理だけで構成され,OSのオーバヘッドは考慮しないものとする。また,新しいプロセスの生成と中断されたプロセスの再開が同時に生じた場合には,新しく生成されたプロセスを優先するものとする。
| プロセス | 生成時刻 | 単独で処理された場合の時間 |
| 1 | 0秒後 | 5秒 |
| 2 | 3秒後 | 7秒 |
| 3 | 6秒後 | 5秒 |
ア.12
イ.14
ウ.16
エ.17
解説
まず最初に生成時刻が0秒後のプロセス1が実行されます。
タイムクォンタムは2秒なので2秒間だけ実行されます。

待ち行列:プロセス1
しかし、プロセス1がタイムクォンタムを使い切った時点で他のプロセスはまだ生成されていません。
したがって、もう一度プロセス1が実行されます。
プロセス1を実行している間にプロセス2も生成されます。
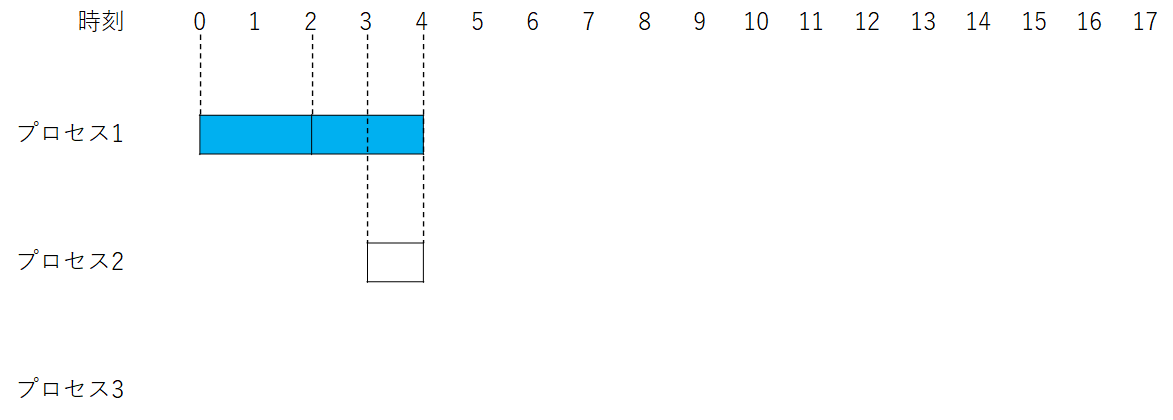
待ち行列:プロセス2、プロセス1
プロセス2が生成されて待ち行列の先頭に並んでいるため、次はプロセス2が実行されます。
さらに、プロセス2がタイムクォンタムを使い切ると同時にプロセス3が生成されます。

待ち行列:プロセス1、プロセス2(、プロセス3)
問題文に「新しいプロセスの生成と中断されたプロセスの再開が同時に生じた場合には,新しく生成されたプロセスを優先するものとする」
とあるので、次はプロセス3が実行され、タイムクォンタムを使い切ると待ち行列の最後尾に並びます。

待ち行列:プロセス1、プロセス2、プロセス3
続いて、待ち行列の先頭のプロセス1が実行されます。
ただし、プロセス1の残り時間は1秒なので、1秒だけ実行されます。

待ち行列:プロセス2、プロセス3
後はプロセス2とプロセス3を交互に繰り返していきます。

待ち行列:プロセス3、プロセス2

待ち行列:プロセス2、プロセス3

待ち行列:プロセス3、プロセス2

待ち行列:プロセス2

待ち行列:なし
プロセス2の生成時刻は3、終了時刻は17なので答えは「イ.14」になります。
【基本・応用情報技術者】スケジューリング
こんにちは。たろすです。
今回はスケジューリングの説明をします。
プロセス
スケジューリングの説明する前にプロセスについて説明します。
プロセスはプログラムを実行する際に、CPUが処理する実行単位です。
プロセスは以下の状態をとります。
待ち状態:CPUが割り当てられても実行できない状態
実行可能状態:CPUが割り当てられれば実行できる状態
実行状態:CPUが割り当てられていて実行中の状態
これらの状態は図のような関係性にあります。

スケジューリング
プロセスをどのような順番で処理するかを決めることです。
スケジューリングにはいくつか種類があるので、それぞれ説明していきます。
到着順方式
名前の通り、到着順(=実行可能状態になった順)に実行していく方式です。
優先度順方式
各プロセスに予め優先度を設定しておき、優先度が高いものから実行していく方式です。
優先度順方式には静的優先度順方式と動的優先度順方式があります。
静的優先度順方式は優先度が一度決められたら変わることはありません。
動的優先度順方式は実行可能状態の時間が長いほど、プロセスの優先度を高く設定し直します。
処理時間順方式
所持時間が短いものから実行していく方式です。
【基本・応用情報技術者】直列接続システムと並列接続システムの稼働率
こんにちは。たろすです。
今回は直列接続システムと並列接続システムの稼働率の説明をします。
稼働率とは?という方はこちらからご覧ください。
https://talosta.hatenablog.com/entry/rasistalosta.hatenablog.com
直列接続システムの稼働率
図のように機器Aと機器Bが直列接続になっている場合、機器Aと機器Bはどちらも稼働していないとシステムとして稼働しているとは言えません。

したがって、システム全体としての稼働率は以下のように求められます。
並列接続システムの稼働率
図のように機器Aと機器Bが並列接続になっている場合、機器Aと機器Bのどちらかが稼働していればシステムは稼働していると言えます。

つまり、システム全体の稼働率は機器Aと機器Bの両方が稼働していない確率を1から引くことで算出できます。
機器が稼働していない確率は(1 - 機器の稼働率)で求められるので、システムの稼働率は以下の式で求められます。
機器が3つ、4つと並列で接続されている場合もすべての機器の稼働していない確率(1 - 機器の稼働率)を掛け合わせて1から引くことで全体の稼働率を算出できます。

